Because of the nature of a number of the materials mentioned right here, this text will include fewer reference hyperlinks and illustrations than typical.
One thing noteworthy is presently taking place within the AI synthesis group, although its significance might take some time to grow to be clear. Hobbyists are coaching generative AI video fashions to breed the likenesses of individuals, utilizing video-based LoRAs on Tencent’s just lately launched open supply Hunyuan Video framework.*
Click on to play. Various outcomes from Hunyuan-based LoRA customizations freely accessible on the Civit group. By coaching low-rank adaptation fashions (LoRAs), points with temporal stability, which have plagued AI video era for 2 years, are considerably diminished. Sources: civit.ai
Within the video proven above, the likenesses of actresses Natalie Portman, Christina Hendricks and Scarlett Johansson, along with tech chief Elon Musk, have been educated into comparatively small add-on information for the Hunyuan generative video system, which may be put in with out content material filters (corresponding to NSFW filters) on a person’s pc.
The creator of the Christina Hendricks LoRA proven above states that solely 16 photos from the Mad Males TV present have been wanted to develop the mannequin (which is a mere 307mb obtain); a number of posts from the Secure Diffusion group at Reddit and Discord affirm that LoRAs of this type don’t require excessive quantities of coaching knowledge, or excessive coaching instances, usually.
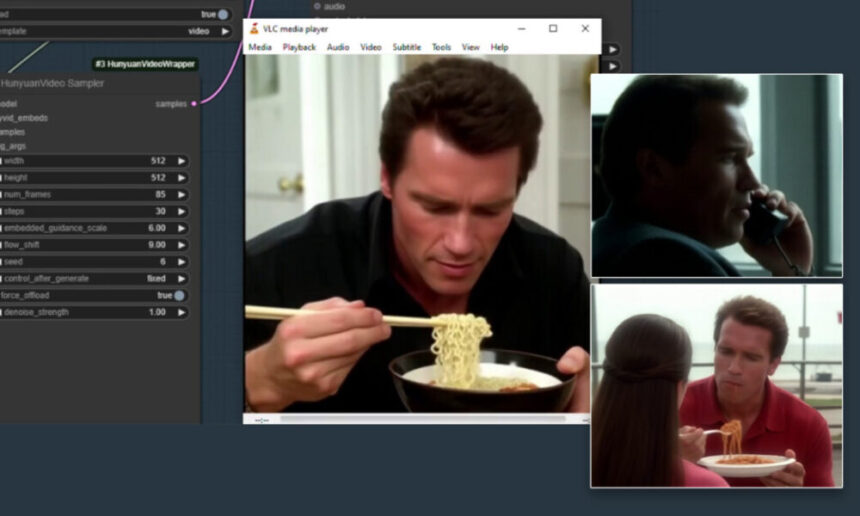
Click to play. Arnold Schwarzenegger is dropped at life in a Hunyuan video LoRA that may be downloaded at Civit. See https://www.youtube.com/watch?v=1D7B9g9rY68 for additional Arnie examples, from AI fanatic Bob Doyle.
Hunyuan LoRAs may be educated on both static photos or movies, although coaching on movies requires better {hardware} sources and elevated coaching time.
The Hunyuan Video mannequin options 13 billion parameters, exceeding Sora’s 12 billion parameters, and much exceeding the less-capable Hunyuan-DiT mannequin launched to open supply in summer time of 2024, which has only one.5 billion parameters.
As was the case two and a half years in the past with Secure Diffusion and LoRA (see examples of Secure Diffusion 1.5’s ‘native’ celebrities right here), the muse mannequin in query has a much more restricted understanding of movie star personalities, in comparison with the extent of constancy that may be obtained by means of ‘ID-injected’ LoRA implementations.
Successfully, a personalized, personality-focused LoRA will get a ‘free experience’ on the numerous synthesis capabilities of the bottom Hunyuan mannequin, providing a notably simpler human synthesis than may be obtained both by 2017-era autoencoder deepfakes or by making an attempt so as to add motion to static photos by way of methods such because the feted LivePortrait.
All of the LoRAs depicted right here may be downloaded freely from the extremely fashionable Civit group, whereas the extra considerable variety of older custom-made ‘static-image’ LoRAs also can probably create ‘seed’ photos for the video creation course of (i.e., image-to-video, a pending launch for Hunyuan Video, although workarounds are doable, for the second).
Click on to play. Above, samples from a ‘static’ Flux LoRA; beneath, examples from a Hunyuan video LoRA that includes musician Taylor Swift. Each of those LoRAs are freely accessible on the Civit group.
As I write, the Civit web site affords 128 search outcomes for ‘Hunyuan’*. Practically all of those are in a roundabout way NSFW fashions; 22 depict celebrities; 18 are designed to facilitate the era of hardcore pornography; and solely seven of them depict males quite than ladies.
So What’s New?
Because of the evolving nature of the time period deepfake, and restricted public understanding of the (fairly extreme) limitations of AI human video synthesis frameworks to this point, the importance of the Hunyuan LoRA isn’t simple to grasp for an individual casually following the generative AI scene. Let’s overview a number of the key variations between Hunyuan LoRAs and prior approaches to identity-based AI video era.
1: Unfettered Native Set up
Crucial facet of Hunyuan Video is the truth that it may be downloaded regionally, and that it places a really highly effective and uncensored AI video era system within the arms of the informal person, in addition to the VFX group (to the extent that licenses might enable throughout geographical areas).
The final time this occurred was the arrival of the discharge to open supply of the Stability.ai Secure Diffusion mannequin in the summertime of 2022. At the moment, OpenAI’s DALL-E2 had captured the general public creativeness, although DALLE-2 was a paid service with notable restrictions (which grew over time).
When Secure Diffusion turned accessible, and Low-Rank Adaptation then made it doable to generate photos of the id of any individual (movie star or not), the massive locus of developer and client curiosity helped Secure Diffusion to eclipse the recognition of DALLE-2; although the latter was a extra succesful system out-of-the-box, its censorship routines have been seen as onerous by lots of its customers, and customization was not doable.
Arguably, the identical situation now applies between Sora and Hunyuan – or, extra precisely, between Sora-grade proprietary generative video methods, and open supply rivals, of which Hunyuan is the primary – however most likely not the final (right here, think about that Flux would finally acquire important floor on Secure Diffusion).
Customers who want to create Hunyuan LoRA output, however who lack successfully beefy tools, can, as ever, offload the GPU facet of coaching to on-line compute companies corresponding to RunPod. This isn’t the identical as creating AI movies at platforms corresponding to Kaiber or Kling, since there isn’t a semantic or image-based filtering (censoring) entailed in renting a web-based GPU to assist an in any other case native workflow.
2: No Want for ‘Host’ Movies and Excessive Effort
When deepfakes burst onto the scene on the finish of 2017, the anonymously-posted code would evolve into the mainstream forks DeepFaceLab and FaceSwap (in addition to the DeepFaceLive real-time deepfaking system).
This methodology required the painstaking curation of hundreds of face photos of every id to be swapped; the much less effort put into this stage, the much less efficient the mannequin could be. Moreover, coaching instances diversified between 2-14 days, relying on accessible {hardware}, stressing even succesful methods in the long run.
When the mannequin was lastly prepared, it may solely impose faces into current video, and often wanted a ‘goal’ (i.e., actual) id that was shut in look to the superimposed id.
Extra just lately, ROOP, LivePortrait and quite a few comparable frameworks have supplied comparable performance with far much less effort, and sometimes with superior outcomes – however with no capability to generate correct full-body deepfakes – or any component aside from faces.
Examples of ROOP Unleashed and LivePortrait (inset decrease left), from Bob Doyle’s content material stream at YouTube. Sources: https://www.youtube.com/watch?v=i39xeYPBAAM and https://www.youtube.com/watch?v=QGatEItg2Ns
Against this, Hunyuan LoRAs (and the same methods that may inevitably comply with) enable for unfettered creation of complete worlds, together with full-body simulation of the user-trained LoRA id.
3: Massively Improved Temporal Consistency
Temporal consistency has been the Holy Grail of diffusion video for a number of years now. The usage of a LoRA, along with apposite prompts, provides a Hunyuan video era a relentless id reference to stick to. In principle (these are early days), one may prepare a number of LoRAs of a selected id, every carrying particular clothes.
Below these auspices, the clothes too is much less prone to ‘mutate’ all through the course of a video era (because the generative system bases the subsequent body on a really restricted window of prior frames).
(Alternatively, as with image-based LoRA methods, one can merely apply a number of LoRAs, corresponding to id + costume LoRAs, to a single video era)
4: Entry to the ‘Human Experiment’
As I just lately noticed, the proprietary and FAANG-level generative AI sector now seems to be so cautious of potential criticism regarding the human synthesis capabilities of its initiatives, that precise folks not often seem in mission pages for main bulletins and releases. As a substitute, associated publicity literature more and more tends to indicate ‘cute’ and in any other case ‘non-threatening’ topics in synthesized outcomes.
With the arrival of Hunyuan LoRAs, for the primary time, the group has a chance to push the boundaries of LDM-based human video synthesis in a extremely succesful (quite than marginal) system, and to totally discover the topic that the majority pursuits the vast majority of us – folks.
Implications
Since a seek for ‘Hunyuan’ on the Civit group principally exhibits movie star LoRAs and ‘hardcore’ LoRAs, the central implication of the arrival of Hunyuan LoRAs is that they are going to be used to create AI pornographic (or in any other case defamatory) movies of actual folks – celebs and unknowns alike.
For compliance functions, the hobbyists who create Hunyuan LoRAs and who experiment with them on various Discord servers are cautious to ban examples of actual folks from being posted. The fact is that even picture-based deepfakes at the moment are severely weaponized; and the prospect of including really reasonable movies into the combo might lastly justify the heightened fears which were recurrent within the media over the past seven years, and which have prompted new rules.
The Driving Drive
As ever, porn stays the driving drive for expertise. No matter our opinion of such utilization, this relentless engine of impetus drives advances within the state-of-the-art that may finally profit extra mainstream adoption.
On this case, it’s doable that the value might be greater than typical, because the open-sourcing of hyper-realistic video creation has apparent implications for felony, political and moral misuse.
One Reddit group (which I cannot identify right here) devoted to AI era of NSFW video content material has an related, open Discord server the place customers are refining ComfyUI workflows for Hunyuan-based video porn era. Every day, customers put up examples of NSFW clips – lots of which might fairly be termed ‘excessive’, or a minimum of straining the restrictions acknowledged in discussion board guidelines.
This group additionally maintains a considerable and well-developed GitHub repository that includes instruments that may obtain and course of pornographic movies, to offer coaching knowledge for brand new fashions.
Since the most well-liked LoRA coach, Kohya-ss, now helps Hunyuan LoRA coaching, the obstacles to entry for unbounded generative video coaching are decreasing day by day, together with the {hardware} necessities for Hunyuan coaching and video era.
The essential facet of devoted coaching schemes for porn-based AI (quite than id-based fashions, corresponding to celebrities) is that an ordinary basis mannequin like Hunyuan isn’t particularly educated on NSFW output, and should subsequently both carry out poorly when requested to generate NSFW content material, or fail to disentangle discovered ideas and associations in a performative or convincing method.
By creating fine-tuned NSFW basis fashions and LoRAs, will probably be more and more doable to mission educated identities right into a devoted ‘porn’ video area; in spite of everything, that is solely the video model of one thing that has already occurred for nonetheless photos over the past two and a half years.
VFX
The massive enhance in temporal consistency that Hunyuan Video LoRAs provide is an apparent boon to the AI visible results trade, which leans very closely on adapting open supply software program.
Although a Hunyuan Video LoRA method generates a whole body and setting, VFX firms have nearly actually begun to experiment with isolating the temporally-consistent human faces that may be obtained by this methodology, with the intention to superimpose or combine faces into real-world supply footage.
Just like the hobbyist group, VFX firms should anticipate Hunyuan Video’s image-to-video and video-to-video performance, which is probably essentially the most helpful bridge between LoRA-driven, ID-based ‘deepfake’ content material; or else improvise, and use the interval to probe the outer capabilities of the framework and of potential variations, and even proprietary in-house forks of Hunyuan Video.
Although the license phrases for Hunyuan Video technically enable the depiction of actual people as long as permission is given, they prohibit its use within the EU, United Kingdom, and in South Korea. On the ‘stays in Vegas’ precept, this doesn’t essentially imply that Hunyuan Video is not going to be utilized in these areas; nonetheless, the prospect of exterior knowledge audits, to implement a rising rules round generative AI, may make such illicit utilization dangerous.
One different probably ambiguous space of the license phrases states:
‘If, on the Tencent Hunyuan model launch date, the month-to-month energetic customers of all services or products made accessible by or for Licensee is bigger than 100 million month-to-month energetic customers within the previous calendar month, You will need to request a license from Tencent, which Tencent might grant to You in its sole discretion, and You aren’t approved to train any of the rights beneath this Settlement except or till Tencent in any other case expressly grants You such rights.’
This clause is clearly aimed on the multitude of firms which might be prone to ‘intermediary’ Hunyuan Video for a comparatively tech-illiterate physique of customers, and who might be required to chop Tencent into the motion, above a sure ceiling of customers.
Whether or not or not the broad phrasing may additionally cowl oblique utilization (i.e., by way of the availability of Hunyuan-enabled visible results output in fashionable motion pictures and TV) may have clarification.
Conclusion
Since deepfake video has existed for a very long time, it will be simple to underestimate the importance of Hunyuan Video LoRA as an method to id synthesis, and deepfaking; and to imagine that the developments presently manifesting on the Civit group, and at associated Discords and subreddits, symbolize a mere incremental nudge in the direction of really controllable human video synthesis.
Extra doubtless is that the present efforts symbolize solely a fraction of Hunyuan Video’s potential to create utterly convincing full-body and full-environment deepfakes; as soon as the image-to-video part is launched (rumored to be occurring this month), a much more granular stage of generative energy will grow to be accessible to each the hobbyist {and professional} communities.
When Stability.ai launched Secure Diffusion in 2022, many observers couldn’t decide why the corporate would simply give away what was, on the time, such a precious and highly effective generative system. With Hunyuan Video, the revenue motive is constructed instantly into the license – albeit that it could show tough for Tencent to find out when an organization triggers the profit-sharing scheme.
In any case, the outcome is similar because it was in 2022: devoted growth communities have shaped instantly and with intense fervor across the launch. A number of the roads that these efforts will take within the subsequent 12 months are certainly set to immediate new headlines.
* As much as 136 by the point of publication.
First revealed Tuesday, January 7, 2025







